Museum of Moms: Tiger Mom
A mom in the Museum of Moms, known for chiding her children into trying harder and expecting the absolute best. After all, other children don’t matter.
For only a quarter, get mommed here: Tiger Mom
Why?
I’ve been missing my mom lately. It’s not a unique feeling in NYC, which in many ways is a city of transplants and transients. With so many people around and so few mothers I find that we all struggle with a bit of loneliness, and while we drown those feelings away with joints and light beers, we can only suppress the feelings for so long.
But… then the holidays arrive and for many it’s when we realize what we’ve been missing all along: a mother’s touch. The kind of love that is comforting, familiar, beautifully unconditional and (let’s be honest) excruciatingly judgemental!
Inspirations
The concept was birthed while playing Butterfly Soup, and finding a lot of humor in Noelle’s asian-mom / tiger-mom stereotypes. At the same time, I’ve been jumping into the world of machine learning and a few projects really resonated with me.
The first, Ross Goodwin’s 1 the Road, is a fascinating and artful attempt at imbuing a neural network with personality. Ross beautifully summarizes his role as a “writer of writer”. In his attempt to build a model that writes like Jack Keruoac, Ross chose to train on everything that wasn’t directly Jack Keruoac but instead poetry and lots of bleak books that had Jack Keruoac’s spirit. I’m now fascinated with this idea of imbuing a neural network with “personality”.
The second project I found fascinating is Speak Memory, where Eugenia Kuyda questionably “ressurects” her recently passed friend, Roman, in the form of chat bot. What I find interesting is that in doing so, she found a lot of comfort for herself. That connection with artificial and comfort is something I set out to explore here.
Idea
The grander idea involves a room full of Zoltar-like, coin-operated moms in the back of a UHaul so that presumably, a visitor can seek out a momming on demand. The flow I’m after:
- User puts in a coin
- Tiger Mom comes alive and accuses you
- A comparison story is generated
- A story is printed
- Tiger Mom shouts a microaggression at you
Goal
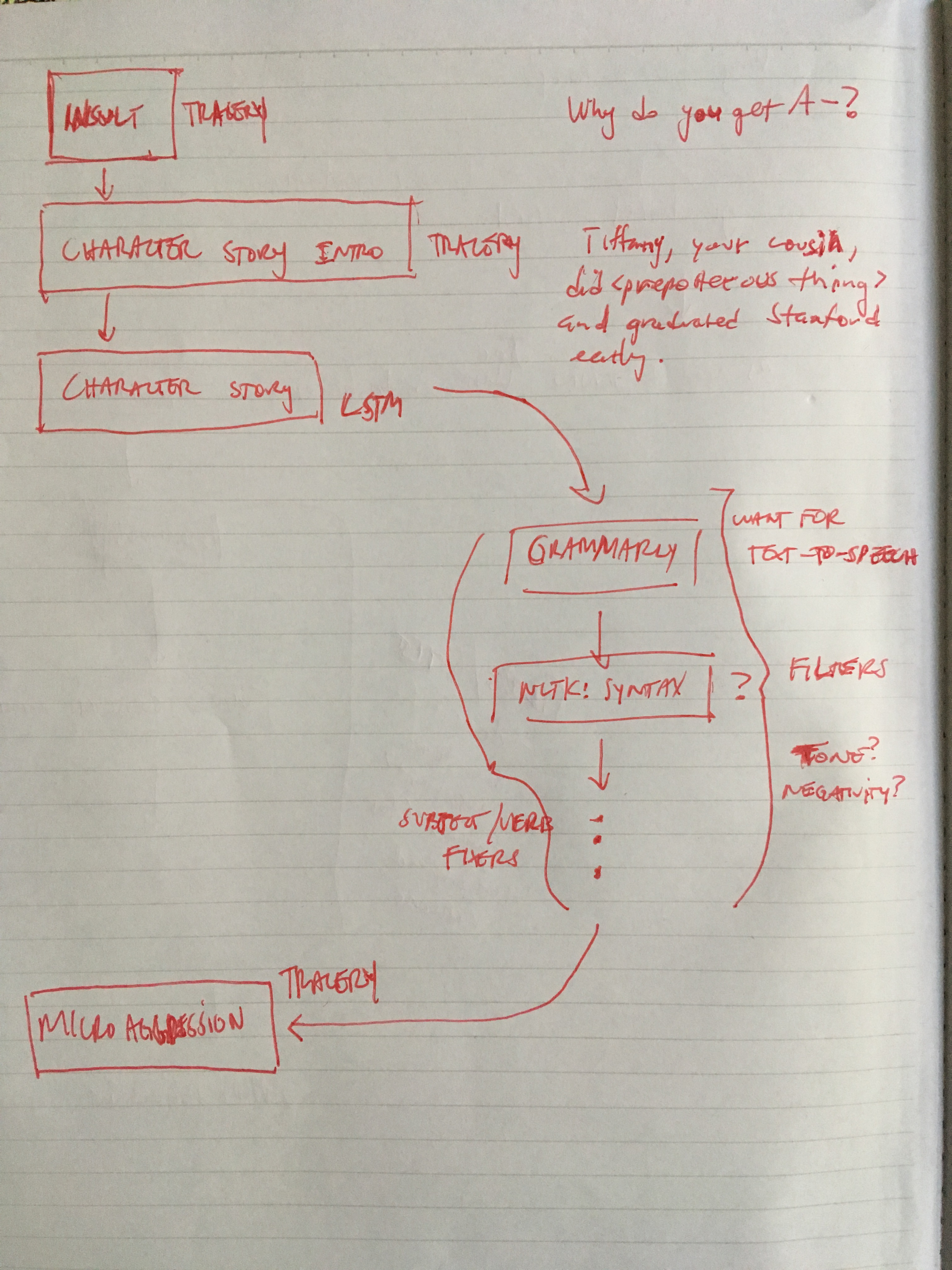
Initially, I wanted to break the conversational piece into a formulaic structure. I distilled the act of “tiger-momming” into a few tropes – the accusation, the impossible comparison story, and the microaggression.
The Goal
Essentially, my goal is to generate these three pieces of the conversation.
Accusation:
Lisa told me you turned in your homework late.
Comparison:
Why cant you be more like your cousin, Nancy?
She got straight As in high school and got into Stanford. She even graduated early and founded a non-profit! Now shes working as a doctor and making the big bucks.
Microaggression
Besides, you have all this free time now that youve given up piano lessons.
First Pancake
This proved to be a rabbit hole. Given another year, I might be able to make this work. I quickly learned that the hard part, which being new to this world I didn’t anticipate, is getting the right data.
As my wise friend Roland phrased it:
You don’t actually need big data. You need clean data and big data.
TO BE CONTINUED… I’ll reflect more on my failures here later, I promise!
- it’s too erratic to be used in a production setting without a complex layer of spell and grammar checking
- data data data
- char-rnn – super popular and quick but not the right model. really wanted a word-rnn and I couldn’t quite find a good model to transfer learn from and I started but soon backed out of building one from scratch.
Markov Chain
As it turns out, Markov chains were better in this case.
To build a model to create the story-like biographies of impressive relatives, I scraped a few hundred speaker biographies from conference websites. I then cleaned that data to remove empty biographies and placeholder biographies and a holy lot of white-space finessing. But luckily, Markov chains require less data to produce something valid than LSTMs! This proved to be a good dataset because speaker biographies are very succinct and factual, in essence highlighting the individuals achievements in a paragraph.
Next, I borrowed techniques from Allison Parrish’s Corpus Driven Narratives Tutorial to subset the scraped biographies into beginnings, middles, and ends. The core idea being that instead of having one model we have three separate models that are each specialized to generate a sentence from a different part of a character’s biography – beginnings trained on the first sentence, endings trained on the last sentence, and middles for every middle sentence. This worked fairly well in giving the biographies an arc as opposed to a list of facts.
Next, we have “filters”, wherein I do some manual manipulation to tie the sentences together. This can get extraordinarily complicated and I’m surprised there aren’t good services for this. T.T
My quick-and-dirty approach focused on two things:
- Fixing names
My Markov chain model generated a lot of names and as you can imagine the subject of each sentence tends to be a different name. I explored seeding each sentence but I think that takes away from the creative temperature. Instead, I created a name generator by scraping a bunch of unisex names. To replace the names in the generated text, I used a mix of spaCy’s entity and part-of-speech taggers. This worked well to some degree but as expected, spaCy gets it wrong often enough to ruin the magic.
- Fixing pronouns
Now that I had control over the names and because they were unisex, I needed to pick a gender pronoun and update the story to use a consistent pronoun. Again, I used spaCys part-of-speech taggers and replaced as desired.
Check out the Colab Notebook.
And various source code experiments here: GitHub.
What’s Next
There’s a lot more polish I want to add:
- Tracery-backed accusations and microagressions
- I had a difficult time marrying my markov model and tracery, which I wanted to share a name.
- Sound! I experimented with Google’s Text-to-Speech API successfully but it’s not clear how to do everything browser-side. And I’m not quite ready to build a server API for this. =[
- I still want to explore LSTMs
- The mom needs more character – sound effects, mannerisms (gaze detection to control appearance?)
Shoutout
Just want to add that I wasn’t actually “tiger-mommed” growing up. Rather, I found it an interesting and strong enough archetype to attempt to build a personality around.
Also, shout out to my pops!